
Towards the end of my post back in march about the near future of agents I mentioned possible changes to the architecture of how Application and UI interact.
Once that hard layer is built into applications and websites, something happens to the way software operates. The UI stops being the only control layer, and becomes the human layer only. The app and the interface become completely divorced.
This idea has basically been the working hypothesis across a number of the group chats I’m in for at least the last year. Over time I’ve been exposed to a great deal of manic experimentation and discussion about this trajectory from some of the best designers I know.
The clearest signs however that the UX layer is actually delaminating from the application layer came this week at Google I/O with their announcement of Gemini 3.5 Flash-powered Google Search results. In real time, an agent will wake up inside of Google’s code-harness software Antigravity, and dynamically build an interactive page of search results similar to the hypertext objects I describe here. You can see the process demonstrated in the keynote below, I’ve queued it up:
Google has been gesturing at dynamic interface generation since the original Bard era; but the most recent I/O made it feel like a real product direction. I’ll also note, that prompting the search box to give you 10 blue links is *exactly* the kind use case that Google want you to use it for!
There are a whole bunch of terms being used describe these kind of dynamic front ends right now, I like On-the-Fly UI (OTFUI), but I’ve also heard: Liquid UI, Disposable Interfaces and Runtime Artefacts used in conversation as well.
The Great Delamination
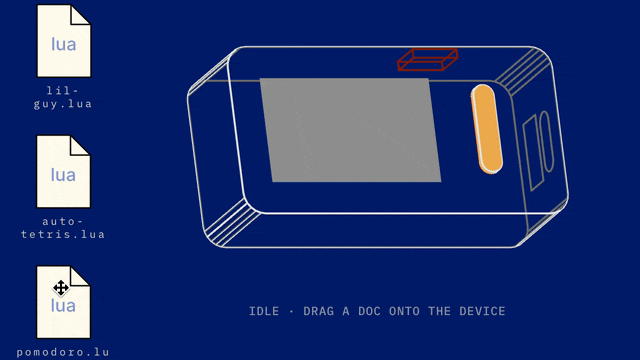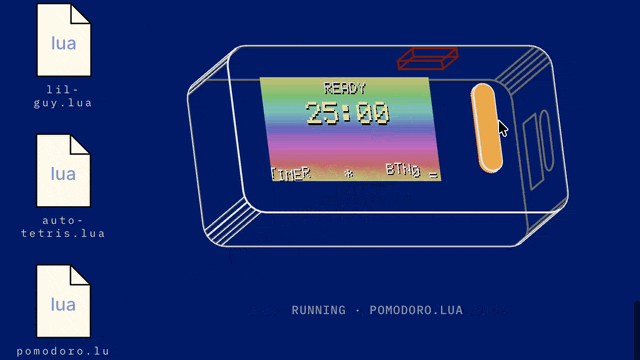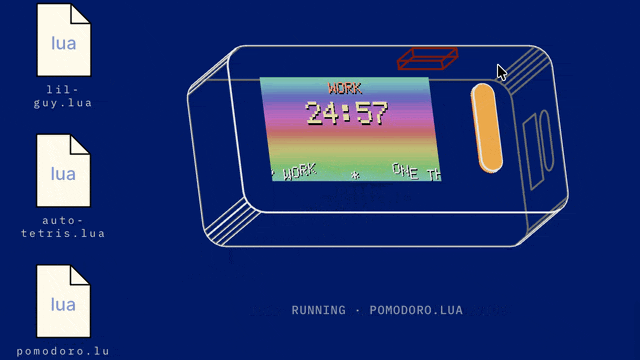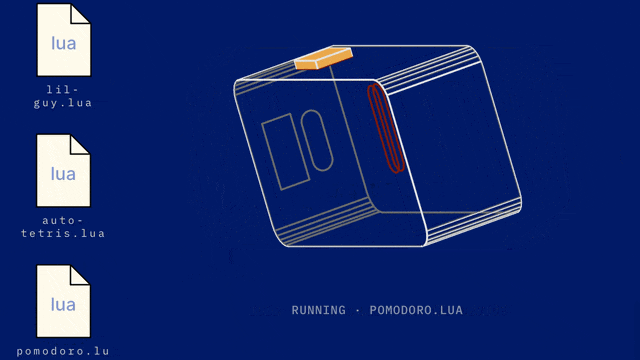
Another place you can see this kind of Liquid UI/UX emerging is on dedicated AI hardware that has a fairly constrained action dictionary. For example, the much maligned Rabbit R1 recently got a massive software update to Rabbit OS 2, and it lets you vibe code apps using text to speech:
Matt Webb is also exploring drag and drop / dynamic UX and software interfaces for AI hardware too at his most recent venture.
Another example can be seen from Manuel Odendahl in this this video where he demos “disposable software“, inspired by Apple’s original HyperCard:
And my friend Ramon Marc has been been exploring dynamic front end interaction patterns for non technical users recently and came up with this last week:
It’s an imagined middleware layer that takes a short intent from the user as a text input, and “Double Diamonds” the idea: exploring what would / could be possible from the limited prompt and then constrains it back down to a set of options and questions to show back to the user to clarify / select and confirm before it generates the actual app.
I kept iterating on unfolding intent to see how it could feel in more practical flows, so this is an evolution of [[sxk4bapy|folding intent]].I kept iterating on unfolding intent to see how it could feel in more practical flows, so this is an evolution of folding intent. The core idea stays the same: a prompt is an intent. It gets translated into a function ([[30bptv1y|inspired by Agentic Algebra]]), which produces a JSON tree, where each leaf is a UI paradigm for more granular user input. I kind of think we’re getting into territory where we can make more contextual, hard interfaces with this. Think: I want pizza from place xyz takes the intent, pulls context from the pizza place, and builds a UI based on the tree and availability.
There is another iteration here, that walks though the intent and surfaces the permissions for the user to grant before execution. Based on the principles of hardness. The goal being that vibe coding liquid UI apps is made simple to users who don’t know anything about coding at all. (more on this further down the post)
So… if UX is going to delaminate from applications, one of the things we need to think about is the speed at which these front ends can be conjured into existence by the bot. In RM’s demo video, you can see the token counter coming in at around 60 tokens per second (tok/s) and the UI taking 22 seconds to generate.
Google’s new Gemini 3.5 Flash model comes in at around 300 tokens a second depending on connection time and latency so if at 60 tok/s, RM’s demo takes 22 seconds, At 300 tok/s, the same token budget takes about 4.4 seconds. But during the Google I/O keynote, they showed off an internal Gemini model running at 1,500 Tok/s. Which is 25× faster! Using the same example this becomes 0.8 seconds. Essentially meaning the UI generation becomes instantaneous.
Iron Speciation Triangle
Given this seems to be an observable trend, I’m pretty sure this is the direction of travel. So we should probably take a step back, and zoom out, to talk about model development in general.
Years ago now, I wrote about “maximal intelligence at all levels”. Local models, cloud models, frontier models, etc, will all speak to one and shunt tasks up and down depending on capability and speed requirement.
General-purpose models like Claude Mythos, the next ChatGPT and Gemini models, are all going to carry on getting better as they have been. I think however, over the coming months, and definitely in the next 18 months or so, we are going to see a speciation of AI models.
We already see the first signs of this with the difference between thinking models and instant models, and also in the open source world where small and extremely performant coding models are being developed. But these are only the embryonic versions of the coming split. There is a lot of headroom to be found by keeping intelligence roughly steady while pushing speed, cost, latency, and availability into completely different regimes. It seems obvious and logical that the major labs will go further than they already are, and will produce different models specialised for different tasks alongside their general purpose build-the-machine-god frontier models.
Imagine for a moment that this time next year there’s a model that isn’t appreciably more ‘intelligent’ than the one you are using today. But it’s extremely cheap, and very fast. As fast, if not faster, than the 1,500 Tok/s model we know Google already have internally.
If we take the classic iron triangle of quality, speed, and cost, but for our purposes we’ll use intelligence for quality. We can pick two and work our way around the triangle to speculate on three distinct future species of machine mind:
- Fast and Intelligent, but not Cheap: These already exist in a way, with both Anthropic and ChatGPT offering ‘fast modes’. These will get used for real-time agents, and developers in high-stakes coding environments. But also high-frequency trading, and tasks that require extremely performant multimodal interaction: robotics, security applications, and even surgery in healthcare. Maybe they are dispatched by general models with a one-off agentic task. They are really fast and intelligent, but you just burn money using them.
- Cheap and Intelligent, but not Fast: This is the kind of use case that we are seeing emerge with Claude’s new “dreaming mode”—batch minds that can be left to run overnight, reading things, doing background memory-consolidation, auditing codebases, simulating and generating reports, planning, and doing deep research. Useful for the kinds of jobs and applications that you don’t necessarily need to run in real time. Tasks that you can wait on.
- Fast and Cheap, but not Maximally Intelligent: This is the baseline model I’ve already explained being used for instantaneous UI generation.
All three of these model species would of course, require vastly different architectures at the data centre level: hardware and memory optimisations, and so on. Also important to note, as a lot of people miss this: The literal, physical substrate that LLMs run on evolves and changes to meet the needs of the software design of the model. These kinds of model species will emerge as more data centres get finished up and more compute becomes available.
Runtime Sovereignty
Beyond the data centre, we also have to consider the emerging ASIC chips for AI, where models are essentially baked onto the chip. Taalas recently entombed Meta’s old Llama 3.1 8B in silicon and achieved speeds of nearly 17,000 tok/s. If a chip like that were running a model intelligent enough to execute the example above, which Llama 3.1 8B is not, the same operation would take about 78 milliseconds or 0.07764706 seconds. 283.3× faster than RM’s demo experiment.
Whilst these kinds of fixed chips can’t be updated or changed, if we end up in the near future with “good enough” intelligence running locally, and insanely fast, then these kinds of Liquid UIs might end up being generated on the edge by the hardware/physical interface. Sort of similar to what I was thinking about when I first wrote about Helpful LLocal Models last year.
If we get this kind of local improvement then the iron triangle becomes a square and sovereignty becomes a new variable. Local actions won’t necessarily be performed by the smartest minds, but they do live on your laptop or phone and are optimised for latency, privacy, persistence, and ownership etc.
In addition to open source coding models, you can already see other kinds of specialised models tuned for speed and subject matter starting to emerge. OpenMed, a terminal-native clinical agent explicitly engineered around strict local compliance, and data sovereignty. Using MLX it clocks 24–33× speedup on standard Apple Silicon for local privacy filtering. OpenMed is a real breakthrough showing that a clinical AI can now live entirely inside hardware that a small local clinic can actually own, inspect, and govern. Note: these things can run on iPhones and iPads too at very usable speeds.
As the capabilities of local models increase, we’ll see all sorts of new agent types emerge, ones that run tasks as batch processes overnight. Very similar to the way that the iPhone has run its machine learning over your photo library for the last decade. Local models will be able to tag, process, read, and summarise all your local files, photos, and documents on the device and produce embeddings for them. Imagine being able to search Spotlight for “recent invoices from X” or “that spreadsheet about Y”.
In a maximal-intelligence-at-all-levels world, the winner wins by proximity
Constitutional Software
With liquid runtime artefacts, the question becomes: who is allowed to generate them, where, with what data, under what rules, and on whose behalf? This is of course a question of governance.
Once interfaces are generated on demand, and actions are distributed between cloud models, local models, specialist models, and device-level agents, the interface is no longer the boundary of the application. It’s a membrane between user intent, available context, permissions, model capability, and machine speed. All of this will require a great deal of what I call hardness.
“What can this software do?” becomes: “what is this software allowed to do?” Which model is allowed to see which data? Which actions must stay local? Which decisions require explicit permission? Which agents can speak to each other? Which layer gets to say no?
It’s all very complicated and will need a lot of governance. In the group chat Rafa has been calling this design space constitutional software.
What rules or protocols govern the generation of the UI. Which screens, tools, agents, and actions may appear and under what circumstances. There is a great deal of future work required if it’s going to become bullet proof.

Subscribing to SSRZ supports my online work and creative projects.
As a thank you, I send you my zine four times a year, just like it’s 1994.
No spam. No email. Cancel at any time.